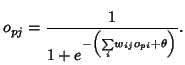4 The attention mechanism
This chapter is about neural attention. It is an introduction to (one of) the main mechanisms of my neural machinery. In retrospect my machinery is in many respects a multi layer ART machine as invented by Stephen Grossberg. My view on it, and my grounds for discovering it, are, however, rather different, and I would like to keep up the distinction because I think this in itself may give some insight.
I begin with a mathematical introduction into pattern associators. After this I construct my neural machine, which I shall call a time machine. To the heart of this machinery we find the attention mechanism and the mirroring mechanism.
It is important that we can attend to more than one thing at a time. The neural network taken as a whole is capable of perceiving, abstracting (immanizing), and remembering perceptual information by way of imagination – among others. In the next chapter I will show that mirroring and imagination refer much to the same process, the difference being that, with regard to imagination time and temporality play a fundamental role.
Asmall, biologically fixed, neural hierarchy
I call the neurons which are connected to the outside world “input neurons” and “output neurons.” Behind these in- and output neurons are other, “hidden” neurons. Behind these hidden neurons are more deeply hidden neurons, and so on. Let us, partly for practical purposes, and partly because of the comparison with our own brains, imagine there to be several layers, or levels, of hidden neurons. To the most deeply hidden layer of these neurons I connect, what I call, an attention mechanism.
Such a layered neural network is also called a hierarchical neural network. In the context of this book one might say that in a hierarchical neural network the more sensory neurons are said to stand lower in hierarchy, and the more hidden neurons are said to stand higher in hierarchy. The attention mechanism is, in principle, connected to the highest neural level. There are not many of such neural layers in our brains. An average of five or seven will be about right.
In order to explain the neural structure between top and bottom of this hierarchy, I shall first give an explanation of the working of a pattern associator. I shall give a more or less ‘standard,’ mathematical introduction from the book “Parallel Distributed Processing,” by David Rumelhart and James McClelland, which made it famous.
[^] What a pattern associator does
A pattern associator has an input and an output side. The trick for a pattern associator is to learn to produce a specific output at a specific, given input. This is done by putting a so-called “teaching input” at this output – so in fact the output side has input from outside the neural network too. The output is said to be clamped into the teaching input’s position. Next the neural network can learn to arrive at this position itself by internally adjusting the weights or sensitivity of its neural connections with regard to this desired output.
The relation between in- and output of a neural network can be very complex. For instance, if you are an oil company and you are drilling for oil, how do you know where to drill? In order to investigate this, explosives and microphones are used. As the explosives are detonated sound waves travel through the surface of the earth. The microphones ‘listen’ to the reflected sounds. It is not easy to detect from these reflected sounds whether or not there is oil in the ground. Luckily, with a neural network we might not even need to understand this relation between sound and oil. Suppose we have a large collection of sound tapes of such explorations and the accompanying drilling results. We feed this information to a pattern associator. At its input we put the reflected sounds, while its output is clamped to either “Yes, there is oil,” or “No, there is no oil.” As such the pattern associator learns from previous explorations whether or not there is oil in the ground. If it proves to have learned this well, then the network can be used for future research and replace human intellect.
Mathematics of adjusting neural sensitivity
How and when to adjust the sensitivity of each neural connection and how to do this at neural level? Starting at the output side we can easily see that the inputs which contribute positively to the state of a clamped neuron should be made more sensitive, whereas those which do the opposite should be made less sensitive. An example of an activation rule which does precisely this is the Widrow-Hoff rule, also called the delta rule. This can be stated as
where
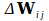
is the change in weight or sensitivity to be made to the connection between neuron
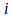
and neuron
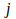
,
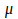
is a constant representing the learning rate,
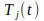
is the teaching input to neuron
– that is the desired output of neuron
– at moment
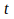
,
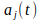
is the amount of activation of neuron
at moment
, and
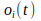
is the output value of (input) neuron
at moment
. It must be said that many variations to this rule exist.
The same rule may be written with regard to a certain input/output
activation pair
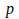
instead of a
moment . If

and
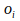
, the activation value and the output value of a certain neuron
, are the same, as is usually the case in models of neural networks, and given that
always equals
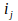
, that is, given that the output of neuron
is the input of neuron
, the delta rule is also given by
where
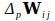
is the change to be made to the weight or sensitivity from the
th to the
th neuron following representation of pattern
,
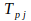
is the desired output of the
th component of the output pattern for pattern
,
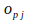
is the
th component of the actual output pattern produced after the representation of input pattern
, and
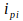
is the value of the
th element of the input pattern.
We take
In other words;
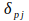
is the difference between the actual and the desired output of a certain neuron with regard to a certain pattern. Thus this
can be called an error signal.
is
not necessarily defined as
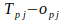
.
Given the above equation for
, we can write the equation for
as
This is called
the generalized delta rule. It is called “generalized” because you can fill in a different
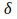
function, as I shall show you. Each may lead to a different behavior of the neural network, with this general formula remaining the same.
Such a rule for changing sensitivity can also be used for neurons lower in the neural hierarchy. Here too those neurons which contributed positively to the desired state of the output neuron should be made more sensitive, and so on. Matters do, however, become more complex here…
It is possible to allow for a certain competition between neurons, which allows for the abstraction of certain features in the information. It is also possible to propagate the error with regard to a desired output back through the network. This idea was first published by Paul Werbos, but it got famous through Rumelhart, Hinton, and Williams, which is where I learned it from.
[^] In this case too, the generalized delta rule is used, but with a differently derived error signal
.
If the neuron is an output neuron, then the error signal is similar to the one of the standard delta rule. It is given by
where
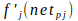
is the derivative of a semi-linear activation function which maps the total input activation to neuron
to an output activation value.
The error signal for the ‘hidden’ neurons, further below in the neural hierarchy, is determined recursively by taking the error signal from the neurons to which they directly connect times the sensitivities of those connections. That is
whenever a neuron is not an output neuron. Here
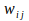
is an element of
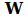
, specifying the weight of the connection from neuron
to neuron
.
Rumelhart, Hinton, and Williams did a number of experiments with neural networks working with these error formulae.
[^] The activation, or output function, they mostly use is given by
Then the error signals are given by
whenever a neuron is an output neuron, and
whenever a neuron is not an output neuron. Since this error signal is determined recursively, the error signal of each neuron higher in the neural hierarchy is needed for every neuron lower in the hierarchy. To my knowledge no biological mechanism for this has been found, and personally I do not think it exists in exactly this way. Neither do I need it for my machine. My machinery achieves error back-propagation in a different way.
Again I say that this is just one example of how a neural network could be built. I must refer you to other works fore a more comprehensive introduction.
Learning the past tense of verbs
David Rumelhart and James McClelland experimented with a pattern associator. They showed that their neural network learned the past tense of English verbs largely the same way children do.
[^] The phenomenon is that children first learn all verbs as if they are irregular. As they master this, they discover or are told that there is a pattern in it. Next they tend to make all verbs regular, including the irregular ones, which is known as “over-generalizing.” Over-generalizing is in fact a form of pattern completion. Next they discover the exceptions to the rule and learn it right again. One could call this ‘an integration-process.’
Since a neural network is a pattern-completer, the first step, of learning everything as if it is irregular, is nothing special. This said it will neither be special that regular parts of the verbs are coming to be recognized. This regularity will be used and integrated in verbs that have been learned previously or that have to be learned yet. This will lead to over-generalization, which will be corrected again later.
From pattern associator to auto-associator
To make an auto-associator from a pattern associator, one connects the teaching input of a pattern associator to its own input. So done, the pattern at the teaching input, in other words, the desired output, is equal to input pattern. As a consequence the network will learn to reproduce the input patterns shown to it. It will tend to do so even from partial information, which turns the neural network in a pattern completion, or pattern reconstruction, machine. An auto-associator is a mirror with a memory.
Earlier I may have given you the impression that immanization is essential for pattern reconstruction. As you see now, it isn’t. It is very beneficial though, and it certainly is important with regard to pattern generation. Immanization is fundamental with regard to giving meaning to things around us. A pattern completion machine alone is mostly a mirror with a memory. That is impressive but it’s not enough. An auto-associator with immanization mechanisms, however, may become quite obstinate. It may, if designed properly, even grow a mind of its own.
Activation patterns of movement
Most things we encounter can move or change. Sounds we hear, for instance, change from moment to moment. With the aid of a simple mechanism a neural network can learn to detect regularities in such patterns-in-time, in other words temporal patterns, and as such detect movement and hear changes in tone. One can think of many variants to this mechanism, but basically one puts either the output or the input of a network through a delay, or phase-shifting network, and then back into the neural network. Such the network has at its input both the situation at this moment, and that of a moment earlier. Then it can make associations between the two. Stephen Grossberg was the first to use this principle, I think.
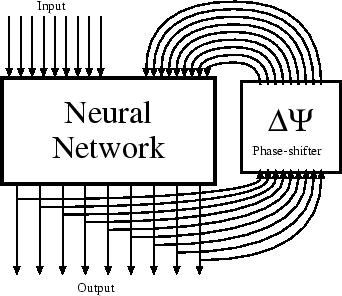
Remark that, although the input of the neural network may present a temporal pattern, the output is not. If you look in a waterfall for some minutes, and then look at something which stands still, then for a while this thing will seem to stream upward, in the opposite direction of the waterfall. This is because the neural network at the lower, sensory levels has adapted to the movement of the waterfall. When you then look at something which stands still, the opposite happens.
Principles of neural attention
Take two pattern associators. Imagine them to have an input side at one end, and an output side at the other end. Lay them on top of each other, but in opposite directions with regard to each other’s input and output side. Then reconnect them such, that each one of them tends to mirror, mimic, or ‘imitate,’ the other, but in the opposite direction with regard to each other. In other words, we connect them such, that both networks act as each other’s teachers – but then a little more complex.
To the input of the first neural network are attached sensory devices like eyes and ears. This neural network I call the deconstructing neural network.
The input from the second network is derived from the attention mechanism. This neural network I call the constructing or reconstructing neural network.
Sometimes I also name the deconstructing neural network the transcendent neural network, since it is relatively transcendent with regard to the constructing neural network, which I then call the immanent neural network.
[^]In stead of the term “deconstructing” and “constructing neural network” I also speak of the “deconstruction” and “construction neural network,” because the pattern or image in the network, as seen bottom to top, or vice versa, represents the deconstruction, or the construction, of something. In other words, both deconstruction and construction begin at one end and are completed at the other end of the neural network. In between one can find the intermediate stages.
[^]I refer to the two neural networks laying on top of each other as “the split neural network.” In reality this is a complex apparatus. For now I will simplify this as much as I can.
At the split in this network a process which I call mirroring takes place. It is essential that the neural activation in each halve of the split neural network is flowing in the opposite direction. I shall take the split to be continuous through the whole hierarchy of the neural network.
In the split neural network, taken as a whole, I take the sensory end to be the bottom, and the other end, that is the side of the attention mechanism, to be the top of the neural network.
Neural activation flowing from the senses to the attention mechanism can also be referred to as forward projection, while downward activation from the attention mechanism to the senses is often referred to as backward projection. This terminology is common in medical, neuro-physiological literature.
Imagine that the attention mechanism does no more than to find a small number of most active neurons in the top of the deconstructing neural network, and then it activates neurons at the same place, but in the constructing network, while depressing all other neurons at this highest level.
[^] As a result there are, from moment to moment, only a few neurons significantly more active at the highest neural level of both the constructing neural network and, by way of mirroring (or maybe otherwise)
[^], of the deconstructing neural network, with still many neurons being activated in the lower neural levels.
Since the deconstructing neural network is mirroring the constructing network, it will tend to look the same and vice versa. But the neural activation in each network is flowing in the opposite direction of neural activation direction!
The apparatus is more delicate than outlined here, of course, but this is the principle. One of the consequences is that we can attend to something through the (re)constructing neural network, while something can attract its attention through the deconstructing neural network.
We disregard motor devices for the moment. In chapter 8 I’ll delve into that.
By the way... It took me ten years to come up with, and make a choice for, the names “deconstructing” and “constructing” neural network, so don’t put too much value on this. Each name will be a metaphor, and because of this it will both lead and mislead you into certain interpretations. In my opinion it is best to think about them in terms of transcendence and immanence.
The mirroring mechanism
I cannot say for sure what the best mechanism for mirroring between neural networks is. I can think of many possibilities.
My guess is that in our own brains the networks selectively and temporally sensitize or desensitize each other, thereby setting out a preferred route for activation within each network. By sensitizing I do, in this context, mean to temporarily facilitate the activation of a certain neuron. This may, of course, indirectly lead to a more permanent sensitivity of the neuron with regard to other neurons. The latter is how I used the word before. The difference is that I then spoke of sensitivity with regard to neural connections, that is synaptic sensitivity, while now I refer to the neuron as a whole becoming more or less sensitive – in fact this is almost the same as what ordinarily happens within a neuron.
The main difference with ordinary neural activation in this case is that mirroring connections have no memory. Their inter-neural strength, or weight, or sensitivity, is fixed – except, I guess, in a global sense, for example with regard to emotional arousal. Above all their weight is relatively small, so that it won’t influence our perception more than necessary. How small? Some instability control mechanism is probably at work here too, and different functions will require different values.
Although the sensitivity between the two neurons in the two halves of the split neural network is itself fixed, their sensitivity with regard to neurons within their own halve of the neural network, of course, is not. So, if a neuron in one network is temporarily sensitized by the other network, then this neuron will become an easier route for neural activation within the first network. As a result chances are that relatively more activation will flow through this neuron. Thereby its sensitivity toward neurons leading to this increased activation will also increase. The net result of both perception and learning is mirroring.
Another option is to conceive of mirroring as a kind of clamping. In that case mirroring would not lead to facilitating neural activation in certain directions. Instead the difference in activation of the two neurons in each neural network is used to change the amount of change in the inter-neural sensitivity of each neuron in each of the neural networks with its surrounding neurons. The sensitivity between the two neurons from each network is itself, of course, not changed.
One can view both of these possible mirroring mechanisms as a form of mirroring by error signals – the error signal being the difference between the actual and the desired mirroring state. These are biologically possible implementations of error back-propagation. In the first case the error signal (indirectly) leads to a difference in activation, and the mirroring by error signals is itself direct, whereas in the latter case the error signal (also indirectly) leads to a difference in sensitivity, and as such the mirroring by error signals is indirect – that is, it functions exclusively through permanent neural change, in other words, it depends on learning.

One could also think of a direct influence of the error signal, having it really activate or deactivate the other neural network a little, instead of only facilitating activation. To me this seems a bit counter intuitive, but the effect will probably not be very different, considering that there is always a lot of neural noise in our brains. Thereby this his been proven to work a long time ago by Stephen Grossberg. I’ll go into this right away.
If the effect of sensitizing a neuron in the other network is too strong then this will lead, if caused by the (re)constructing neural network, to hallucinations, or, if caused by the deconstructing network, to a more or less total conditioning of thoughts and behavior by the outside world. I think the latter is for instance not unusual in situations of great fear, where people do things they normally do not want to do – I think of situations like war, rape, and intimidation. There may be quite a complex apparatus in our brains guiding all these processes.
Grossberg’s Adaptive Resonance Theory
In 2008 I discovered that Stephen Grossberg has long ago (1976) invented, build, and wrote about a machine which is so very much like mine, that he should receive the credit for being the first to have invented such a machine. Grossberg named his theory Adaptive Resonance Theory – ART for short – and the networks are called ART neural networks. These exist in many variations.
[^]Despite the similarities our language is rather different and there are important differences in our machinery too. One remarkable difference is that Grossberg does not have what I call a mirroring mechanism. This may seem so essential to my machine that one might wonder how our machines could be compared. In stead of a mirroring mechanism Grossberg invented a clever stabilization system. The working of this has similarities with what I called phased bounding in chapter 3, but there are differences, and Grossberg finishes where I left of. He truly uses control mechanisms in an engineering way, while I left open any exact use. He uses it specifically to get what I call a mirroring mechanism.

The figure above shows my machinery compared to what a multilevel ART machine could look like – I deliberately changed the outlook a bit to make it comparable to my machinery. Except for the absence of the mirroring mechanism in the ART neural network one also notices that, while I put the so called “long term memory” (LTM) inside a box, Grossberg puts this outside of it. The other way round Grossberg puts the so called “short term memory” (STM) inside a box, while in my scheme it is on the outside and more implicit – I refer to it in terms like that the attention mechanism “holds on” to something for a few seconds.
“Long term memory” (LTM) and ‘short term memory’’ (STM) are well known terms in cognitive psychology. “Short term memory” is often also called “working memory.” In my theory the short term memory referred to in cognitive psychology will be placed somewhere else – see chapter 5, page 79 and further. Grossberg’s short term memories (STM from now on) are in between what I call neural levels, and vice versa.
I am not going to explain Adaptive Resonance Theory in every detail, I’ll just give a functional description. For clarity let us only look at the lowest two levels. The idea is that the top-down signal from neural level 2, through STM
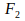
, should not on its own be able to activate STM 1, because that would lead to hallucinations. In order for the process to start an input-pattern should be able to activate STM
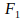
if there is not yet a signal from the higher neural level through STM
. “Gain control” ensures that this is the case. This works by taking gross averages of neural activation, and from this providing overall stimulation or depression of neurons in the neural network in ways comparable to my idea of activation bounding. The higher STMs internally behave as winner-take-all, competitive neural networks. As such they are attention mechanisms.
A sensory, input signal can activate STM
on itself when STM
is inactive. This works by the gain control stimulating STM
as long as no signal arrives from STM
. This starts the process.
Next, based on the bottom-up, deconstructive pattern, the higher neural level produces a top-down, constructive pattern, and presents this to the lower neural level. Now a kind of mirroring takes place, but using ordinary neural activation in stead of sensitization. If the two patterns do not match, then the output of the lower level neural network will decrease, and this will trigger a reset of the higher level neural network, by way of a nonspecific arousal wave. The higher neural level will then try again with a different top-down, constructive pattern, and so on, until a well enough match is found, at which moment the ART neural network is said to “resonate.” By this is meant that the bottom-up and the top-down pattern strengthen and reproduce each other.
Only when such a match occurs, learning will take place, by adapting neural sensitivities. It occurs automatically since prolonged activation only happens when top-down and bottom-up patterns match, and resonance occurs.
I must say that to me the term “resonance” seems confusing. Resonance to me is about something “vibrating,” and this is exactly what an ART network does when it is
not in what Grossberg calls a resonant state, and what it does not when it
is in what Grossberg calls a resonant state. I mean, an ART network vibrates continuously in a noisy and low-volume way as along as the patterns of STM
and STM
do not match, because then the network will continuously be reset. Shouldn’t the “resonant state” better be called “self-reinforcing state”?
As such we have, strange but true, mirroring without mirroring, with the two supposed-to-be-mirroring neurons being a single neuron which is placed both in the constructing and the deconstructing neural network. Marvelous!
What else is my idea of sensitization without memory, than what happens within any neuron? The only thing special is that in my system the mirroring of the constructive network does not directly seem to influence that of the deconstructing neural network and vice versa – at least not necessarily. In Grossberg’s system activation, for instance, adds up even if the neuron is hardly activated, and the combination of bottom-up and top-down stimulation may activate a neuron which would otherwise not have been activated – but through noise my network won’t behave very different, as I shall explain in a moment. His stabilization mechanism, of course, helps to prevent this to happen too much, but it will happen. This might be beneficial with regard to learning and creativity. It might also hinder it. Experiments or mathematics should be able to decide what is best.
My system, further more, may have the advantage that mirroring can be non-linear.
I don’t know whether I can speak about “my” neural network versus “Grossberg’s” neural network anymore, since in many ways it is Grossberg’s, but for clarity I will keep doing so… In my description of my neural network I hardly refer to stabilizing mechanisms, but I do assume them to be there, of course, for reasons explained in chapter 31. They exist with regard to both the constructing and the deconstructing neural network. Remark that, with regard to the ART network in the figure, two times minus is plus, so we may swap around some of the minuses and pluses.
On the surface a difference between Grossberg’s theory and mine is that I do not need the stabilization mechanisms for the explanation of the working of the attention and the mirroring mechanism. This leads to differences such as that for Grossberg “resonance” is the key term with regard to consciousness, while for me it is just something that co-occurs with it for other reasons.
If my network is noisy, then mirroring through sensitization is in fact equal to mirroring through activation below threshold, and then I do need to take into account the control mechanisms in the detailed way that Grossberg does. It is not easy to see intuitively how compatible all these mechanisms are, or which principle is the best for which problem.
ART neural machines have proven to learn very rapidly compared to back-propagation machines, and they do not suffer from massive memory loss of previously learned information. Since analytically Grossberg’s machinery is probably almost equal to mine, these properties should also hold for “my” machinery.
Error back-propagation through mirroring
In the neural network of my design the error signal is not propagated backward through the neural network producing the error, as was the case in the mathematical model using error back-propagation described earlier. What is propagated backward is an image which is more or less a mirror image.
Do we have the problem of the chicken and the egg here? Which one was first, the image propagated backward, being a mirror image of the image in the deconstructing neural network, or the deconstruction image, being a mirror image of the image constructed in the constructing neural network? This problem is fake. All I need to prove is that the content of the two networks have a slight tendency to be equal, without them determining each other too much. Then a little noise will finish the job.
The content of the network should be determined by the outside world. The more strongly the deconstructing network actively mimics the constructing neural network, the less influence the sensory devices have.
In our brains the amount of mirroring is most likely flexible and controllable. The more difficulties the attention mechanism has with attending to something, the more the deconstructing neural network should mirror the constructing neural network in order to help the attention mechanism to gain a hold – with all its complicating consequences regarding the trustworthiness of our perception. I won’t draw out the detailed machinery here. It is clear from the examples that I have given with regard to stabilization, that it is possible in principle, and even rather easy, to achieve this – except for the fact that it is rather complex if taken all together, not to mention all the chaotic processes taking place, a chaos which puts us all, without exception, in danger of going mad.
The deconstructing and the constructing neural network are each others backward propagating networks. What is propagated backward is not an error signal but still, the difference between the two networks may lead to an error signal, which in turn leads to the mirroring of the two networks.
Of course error back-propagation does often not succeed this way, but even if this is a problem, we should remember not to over-estimate our own abilities in this respect.
The attention mechanism as teacher
Simplifying the working of my neural machinery, we can view the deconstructing neural network as a pattern associator, with at one end sensory input from our eyes and ears, and at the other, ‘output’ end, the attention mechanism. In this view the attention mechanism provides the teaching input for this neural network. The particularity here is, that this teaching input does not come from outside the thinking apparatus, neither is there a homunculus. The attention mechanism causes the ultimate competition between output neurons by letting only one, or a few of them, win – in case of human vision, about five may win.
In the other direction the constructing neural network has the attention mechanism at its input, and the sensory devices at its output. As such the sensory input is the teaching input of the constructing neural network.
[^] It is more or less taught to reproduce the perceived outside world within itself.
The deconstructing and the constructing network taken together provide for the analytical capabilities of the whole neural network – that is: us.
The neural network of my design is split in such a way that it is not only a pattern associator, but also an auto-associator. It can imagine, and even hallucinate things – although the latter is not what we want of course. This has a number of functions, one of them being to help to immanize the deconstructing halve of the neural network.
Memory through reconstruction and the structuration of reality
In the split neural network of my design the activation pattern in each network will tend to look like the activation pattern in the other network except for the fact that it flows in the opposite direction.
Essential to this design is, among others, that, in the constructing neural network, the activation pattern is remembered as if it came into being only by the activation of the attention mechanism – which is, both historically and actually, not true because of the mirroring mechanism. The same principle holds for ART machines – it is just a little less evident on the outside.
In the deconstructing neural network, the activation pattern is remembered as if it came into being only by activation through the senses – which is not true either.
A consequence of the former is that the network can reproduce an image, without the aid of the deconstructing network, by the attention mechanism somehow, ‘willingly’ attending to it.
If this happens, then we, through the deconstructing network, will tend to attend to something which looks, sounds, feels, tastes, or smells like something in the outside world, or, if it is not there, it will lead to imaginations – or even hallucinations. Just think of ice cream when it’s hot, and you know what I mean.
The other way a consequence is also that our senses can, through the deconstructing neural network, make us ‘unwillingly’ attend to something, without the aid of the constructing neural network. Hypnosis is an extreme example of this. Here the voice of someone else gets more control than usual over our thoughts and actions.
Because of the structuration – a term from Anthony Giddens
[^] – of the deconstructing and the constructing neural networks by way of mirroring, the deconstructing neural network tends to see things the way it already knows things to be. New facts remembered instantaneously then, are new combinations of old facts.
Giddens uses the term “structuration” with regard to social and linguistic processes, where individuals keep up social structures and language by acting according to them. I like to see this as a kind of mirroring between a structure, and an active element within this structure. This idea is attributable to individuals with regard to their culture, but also to words, for instance nouns, with regard to sentences and language at large – this idea gives, of course, many clues as to how language and speech may work.
Remark that structuration requires an intelligent machine. Self-organization or stabilization is not enough. Some people have very complex thoughts about it, but in my opinion it is rather simple; something is stable because it is stable. If someone wants to call this “self-organization,” fine with me. I mean, if in the chaos of the universe by accident certain molecules, or whatever, come together, stay together, and hold of others, because of certain mechanisms, then we say we have something stable. But this has nothing to do with structuration. Neither has any typical ecological system anything to do with structuration, except where intelligence comes in.
By the way, with regard to the working of structuration in our brains in social and linguistic reality, I think that one, other than one might think at first thought, should place social structures and language on the sensory side, and the elements, such as ‘I,’ ‘you,’ ‘we,’ ‘he,’ and ‘they,’ at the attention side. In between structure and element reconstruction and deconstruction takes place. This accounts for internal structuration – I’ll go into the details in later chapters. This is, within western language communities at least, a little counter-intuitive, because we tend to think of structures as being higher in hierarchy than its elements. External structuration is achieved through our actions in the world.
Last, but not least, the easier it is for the attention mechanism to attend, the stronger the mirroring can be, and the better the thing attended to can be remembered. In plain English: the things you know best are remembered best. This could make that you may fail to see small changes. On the other hand, if there is some kind of feed-back mechanism at work that tries to keep the difficulty of the attention mechanism attending to something constant, then one would, to the contrast, see more peculiarities and differences with regard to things one knows best.
Vulnerability and fault-tolerance of immanent neural networks
What if an immanent neuron dies? Would this disrupt the system? Or is the system already fault-tolerant?
Take an artificial, fully immanent, localized neural network. The activation in such a network is, even though it is immanent, distributed too, of course. The difference is that the designer and observer of such a network in advance names and uses the neurons as replacing this or that. As such neurons stand by definition for the thing to ‘see’ or be ‘seen’ by the network.
Since any neural network is somehow a distributed neural network, in an immanent neural network too there are always many neurons more or less active. For instance, a neural network might recognize a book, which activates a neuron for ‘book,’ but then very likely also neurons that replace ’letter,’ ’word,’ ‘black-on-white,’ and so on will be activated. How to deal with this formally? There is the option of comparison, and there is the option of hierarchy.
By comparing the activity of each neuron the scientist-creator of the network can decide which neuron is most active and take that as the ‘result.’ For us this may seem of little use, since we want to do without this scientist, but, first, do remark that the scientist here does conceive of a certain hierarchy in the activation of neurons – I mean, there are less activated neurons and there are more activated neurons – and second, notice that the attention mechanism exactly does what we ask of the scientist to do, namely, select the most active neuron. Taking these two together we have found our mechanical homunculus.
As I will show there is, in my kind of neural network, always some kind of hierarchy in one way or another, most of which has little to do with the physical neural hierarchy. Among others, neurons on a lower level may ‘stand for’ or ‘replace’ parts of an object ‘seen,’ such as letters and words, while at the highest level there is only one, or only a few, neurons active which ‘stand for’ or ‘replace’ the thing as a whole, for instance a book. As such the ‘standing for’ neuron at the top is the more immanent neuron, but the others are immanent too.
Would a system with such a hierarchy be very vulnerable with regard to dysfunctional neurons? The artificial, fully immanent network in which the meaning of each neuron is predefined would indeed be vulnerable. But in my kind of network, in which immanence can arise without the help of an external designer, there will be little problems. Imagine a most immanent neuron that replaces books would die. If so, then the network still recognizes letters, words, and so on, and it may know of many concrete books or titles, and so on. Further more, there are many transcendent neurons that may become immanent and may come to replace books, in fact many of them will already almost do so. Thereby, there will always be a winner neuron. Where will we find it? In between all these neurons that have something to do with books. So, if it is not already there, then in no time there will arise a replacing immanent neuron.
There is more to say on this topic but for now we conclude that an immanized neural network can be fault tolerant if it is not a fully immanent network.
Images versus activation patterns
The images I am speaking about in this chapter are mostly not conscious-kind-off images which we can be conscious of in some kind of photographic way. This neither means that they are in all respects unconscious. The word “image” should for now be interpreted as referring to an activation pattern. Personally I like to say that we can
experience these images, but then I define “to experience” as “to know that something is absent.” If you know that something is absent, then you know what is missing. As such it is present again. To know that something is missing fits Lacan’s definition of the unconscious, but I do not necessarily mean exactly the same.
[^] Neural activity bounding by attention
Above I said that the attention mechanism would, while deactivating most neurons, activate a few neurons. Is the latter really necessary? Remember the consequences of the silencing of a neural group by the master neuron. Compared to this an attention mechanism could just be a neural activity bounding mechanism which is so sensitive, that it depresses the whole top level network, if the activation of only few neurons in the highest neural level comes above a certain limit.
This bounding limit may be almost zero in a hierarchically structured network in which the attention mechanism is only attached to the highest neural level. By this I mean that the activation of, say three neurons, is enough to silence the lot. If so then there can, in the highest neural level, be only three, or a few more, neurons activated at a time, leaving all other neural activation to lower neural levels. The figure above is a metaphorical representation of this idea.
I conclude that, except with regard to its selectivity, the attention mechanism is alike the activation bounding mechanism. When I spoke of the activation bounding mechanism, however, I did not speak of a split neural network yet with neural activation flowing in a backward direction too, and this, of course, is what really makes the attention mechanism an attention mechanism.
In other words: The question is whether the term “attention mechanism” refers to the selection device which we find at the top of my neural network, or whether it is also a feature of the neural network as a whole? The answer is that the word “mechanism” contains both meanings. As a distinct apparatus, the attention mechanism is the piece of machinery found at the top of the neural network. But as a principle it is more. This principle is embedded in the neural machine as a whole.
Immanization by attention
As a result of the activity of the attention mechanism there will, for every image that the network can reproduce, arise a neuron which will (1) be the most active neuron when the specific image is recognized, and (2) from which, when this neuron is activated by external means, the image will form itself. Please imagine the consequences of this! I need to trigger only one neuron to recreate an image. The whole network should also be structured such, that, if this neuron would die, one of its neighbors takes over its role.
It is clear that these neurons are the most immanent neurons. Earlier I used the term ‘immanent’ with regard to neurons which are immanized by master neurons. Since the immanization by the attention mechanism comprises not just the state of a single neural group, but that of the neural network as a whole, its impact is much larger.
Neural layers
The build-in hierarchy of the neural network in our brains is such, that there are several stages of immanization between lower level neural groups and the attention mechanism. There is not just one group of hidden neurons, but a number of layers of hidden neurons. Each layer is at one end connected to a ‘lower,’ more sensory neural level, and at the other end to a ‘higher,’ more hidden neural level. The lowest neural level is connected to sensory devices and motor mechanisms, while the highest neural level is (connected to) the attention mechanism.

Consider this network to consist of a handful of layers between top and bottom, and consider these layers to be connected to each other in a rather complex way, much more complex than the figure below suggests, with more than one attention mechanism and a lot of, more or less specialized, neural networks at each level. Certain sensory devices, our eyes in particular, will have more lower levels than others, with rather complex interconnections.
By the way, what we usually call our ‘higher’ brains, are in fact, in many ways, the lower parts of our brains, despite the fact that they are evolutionary younger. They are in many ways on the sensory and motor side of our brains. They do, however, elaborate the decisions taken by our reptile brains – the hippocampus, thalamus, and so on – very much. So in a subjective sense we are indeed right to call these young brains the “higher brains.”
Please imagine how a sensory pattern is turned more and more into an attention pattern as it goes through all the layers of the network from bottom to top. Also imagine what happens the other way round.
Cortical clues
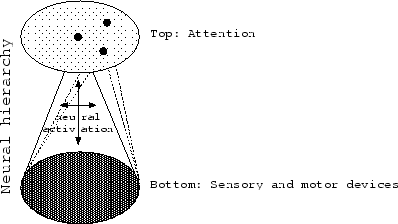
Looking at what is known about the anatomy of our cortex – which is relatively little – I think that the immanization by the attention mechanism takes place in maybe 3 to 8 steps. I think this is equal to the number of levels that the neural hierarchy of the cortex consists of.
If we divide the cortex into the six well known cortical layers and draw the cortical projections between some of them, than we roughly arrive at something like the figure above – here I am making a lot of guesses. (Please don’t confuse cortical layers with neural levels.) Only layer II, III, and IV are named here, and of course the hierarchy involves more steps, and contains many more branches. I think that each of the 100 or so cortical areas is a distinct piece in a neural level, having its place somewhere in the hierarchical tree of the larger neural network. In this picture straight lines are projections within a neural level. Bend lines are projections between neural levels.
In this picture, deconstructing neural activation flows from left to right. Constructing activation flows from right to left. We see that both of these activation streams connect to the other at a certain interval. We see that the lessons, which the deconstructing and the constructing neural network teach each other, must take place somewhere in or between cortical layer II and cortical layer III.
[^] Asmall hierarchy of lower level attention mechanisms
Immanization by the attention mechanism – at the top of the neural network – is very powerful, but it benefits a lot from immanization caused by other, lower level attention mechanisms. Think of all the things we seem to do more or less automatically, and yet in a structured and orderly way, with things immediately getting our attention when needed. For completely automatic tasks one might not always need immanization, but often even simple tasks require some recombination of facts, and this is greatly helped by lower level immanization.
It is largely natural for a neural network with an attention mechanism to automatically develop lower level attention mechanisms. After all, what else is an immanent neuron within the constructive neural network other then a small attention mechanism! But is this the case with regard to lower level neurons too? It is indeed, indirectly, through the mirroring mechanism. So in this sense we do not need any special machinery – it’s a funny idea that an immanent neuron within the deconstructive neural network is a kind of attention mechanism with regard to higher neural levels too, but this is experienced as the drawing of attention.
Remark that up till now we implicitly assumed that bottom-up and top-down connections are excitatory, since master neurons only act locally. General, overall inhibition is taken care of through stabilization mechanisms. This said I think that it would be beneficial if the silencing by some master neurons would be transferred to the neural level below through the constructing network. There are some facts which suggest this to be the case.
A well known fact, which suggests that this is the case, is that people with brain damage often suffer from epilepsy. Epilepsy will often be more encompassing when higher neural levels are damaged, such as our temporal lobes.
In our brains there seem to be two, separate feed-back networks. It is known that cortical feed-back projections originate from two separate cortical layers, and also project into two separate cortical layers. Since it is highly unlikely to have in our brains both excitation and depression without separate projections, this suggests that only the constructing neural network has inhibition between cortical area’s.
As such I think that each neural level will, through inhibition, truly function as a kind off attention mechanism for levels lower in the hierarchy, and maybe also for other neural area’s at the same neural level.
More detailed, the top-down inhibition will not be very strong, I think. It will require more than one top level master neuron to silence a lower level neural group. The structure will, I guess, probably be biologically fixed in the sense that there is no learning at work. There is just a small hierarchy of attention mechanisms. High in the network there is a lot of silencing, and at lower levels this will be less.
The big difference with regard to the top-level attention mechanism is, that the lower level attention mechanisms work much more local, meaning that every neural level, except the top neural level, has thousands, or millions of small-range attention mechanisms, each ruling over a limited piece of neural tissue, and partly, together with others, ruling over some neural tissue at lower levels. Yet they are governed by the master attention mechanism, so they will not gain a consciousness and identity of their own.
The hippocampus & anterograde amnesia
For a complex of reasons I think that, from the perspective of the cortex at least, attention initially stems from the hippocampus and associated structures, and therefore I guess that the difference between reptiles and mammals is largely that the latter has ‘lower-level’ neural networks that are capable of learning, being the cerebral cortex, and the former has not. This physiology makes it likely that emotional arousal and instincts can interfere rather directly with the attention-mechanism and gain lots of control on our seemingly voluntary actions. Except for sexuality and aggression this is especially noticeable in non-humans. It is in accordance with some famous cases of human brain-damage too – I think of “H.M.” – if you take into account that, if you lose lots of the attention-mechanism at a later age, lower-level neural groups will by then have been trained to take over much of its function. So, in effect you ‘only’ lose your temporal, ‘declarative,’ or ‘epic’ memory with regard to new things – that is anterograde amnesia.
Reptile and bird brains
Since reptiles have no cerebral cortex and the hippocampus, in which I suspect our attention-mechanism to be, is its highest organ, one can imagine the reptile to go about the world from one thing to another, hardly having an overview.
To my knowledge, in the brain of a bird the hippocampus and the basal ganglia are further developed. Isn’t it true that, where we live at a place in the world, they live, and fly, at a moment in time? This makes birds quite ‘programmable.’
Manic-depressive syndrome
Real, often congenital, manic-depressive psychosis is, I think, based on an imbalance between the transcendent and the immanent neural network, or in the attention mechanism. In manic moods the influence of the constructive neural network will be too strong. In depressive moods it will be too small.
I do, however, think that an impossibility of a single attention-mechanism to form a pattern, or an overly active or inactive attention-mechanism, might account for manic-depressive-like behavior in people who have had traumatic experiences, or who are very narcissistic, or who suffer from the so-called border-line syndrome. These are very wild guesses.
Attention versus immanization
It may be evident that attention leads to immanization, but does immanization always involve an attention mechanism? No. The way master neurons work, for instance, cannot always be called attentive. There is the element of selection, but what may lack is the element of ’positive’ feedback, that is (re)production or (re)construction. For this we need mirroring, or an ART-like mechanism.
What do we get when we add mirroring? Something like attention, but whether we call it such is a relative matter. If the silencing by the master neuron is such that only a few neurons will be left active then we would tend to call it attention. If more stay active, then we would tend not to call it so. We might, on the other hand, also conceive of this as more points of attention over smaller area’s, in other words a multiple attention mechanism.
Double work
As a consequence of the local working of the master-neurons much work will be done double by different neural groups. Many neural groups, learn the same lesson. This is very important with regard to spatial matters and is therefore most clear for the primary visual part of the neural network. The light of the things we recognize does not always fall at a fixed place on the retina. But, this is only so for the more basic visual elements. The eye-muscles continuously move about 60 to 80 times a second. If they don’t, you’re blinded.
The double work becomes more and more useless at higher levels of abstraction. At higher neural levels an increased level of specialization is more efficient. There the attention-mechanism makes each neural group relatively different in stead of letting them stay relatively equal.
At the highest level things are, in this highest level itself at least, rather disconnected because only five things or less are foregrounded at a time. One could say that at the highest level of the neural network things are connected in time rather than in space – but not without the aid of lower neural levels. This works out at lower levels.
Differences between overlapping or non-overlapping neural groups are in principle established at higher neural levels, but I think that with regard to vision in primates this works a little different. The primary visual cortex of primates is different from that in other species. I think it has a limited, small scale, size-dependent recognition of simple shapes build in. The reason is that this enormously increases the accuracy to see depth in complex structures. To creatures that jump around in trees this is no doubt advantageous because of the chaos of small branches and leaves that trees consist of, and in which the jumping animal must estimate a distance with great precision. As a secondary advantage the labor of recognizing different lines, and so on, is more easily spread over a number of neural groups, so this will become more diverse and accurate too.
Attention versus focusing
Next to the attention mechanism mentioned above there are many other mechanisms which deserve the name ‘attention mechanism’ equally well. Take for instance the many mechanisms that make us physically direct our head and eyes toward something. I further more think that there are some inborn mechanisms which make that we are mentally adapted to a three-dimensional world at birth. Although we can mentally focus at something with the attention mechanism as described above, we can probably do this in other ways too. For this there is, among others, in the older parts of our brains, a kind of two- or three-dimensional neural focusing mechanism.
[^] This works intimately together with the attention mechanism.
Attention versus “top-down processing”
What I also do not mean by attention is, what cognitivists call, “top-down processing.” Of course any network has selectivity. Every network tends to ‘see’ what it already knows, because that’s how it’s made. If it does not do so, then you don’t call it a neural network but a muddle of neurons. This is certainly not to say that this kind of ‘attention’ is not important. I just think that the word ‘attention’ should be reserved for something else – but I do hesitate a little since English is not my mother’s tongue.
Connectionism versus cognitivism
In connectionist terminology the result of the activity of the attention mechanism is that the representation of the content of the network becomes both distributed (read ‘transcendent’) and localized (read ‘immanent’). Since cognitivists typically use localized representational schemes, I bring together cognitivist and connectionist thought.
Positive and negative neural activation
At the present a difference between biological and mathematical neural networks is that most mathematicians build their networks such that any neuron can both activate and deactivate any other neuron, by allowing positive and negative neural sensitivity, or by making it possible for neural activation to be both positive and negative, or, most often, by allowing both sensitivity and activation to be positive and negative. It is very unlikely that this is possible in biologic networks in a strict sense. There only master-like neurons are able to inhibit other neurons. It is sometimes claimed that this makes a difference. However, it is also true that the neurons of our own brains are never silent. As such negative neural activation may simply mean to have less neural activation than average. In a linear system this is mathematically equal to allowing negative activation. In a non-linear system this might not be so, but this depends on the characteristics of the neuron. It is anyway very well possible.
What might make a difference is that, in a neural network in which negative activation values do not exist, inhibition turns activation toward zero, making the activation of a neuron smaller, rather than making it bigger in the negative direction. But if some noise is to be taken as ‘zero,’ then even here ‘no activation’ will mathematically be ‘negative activation.’ One could also introduce a third kind of neural connection, being a silencing connection, which tries to bring the activation of a neuron toward a ‘mathematical zero.’
For implementing my idea’s electronically, one could use ordinary neural networks, with both positive and negative neural activation. When there is no noise in the system this might even be necessary. One should, however, add master neurons nevertheless, in order to stimulate immanization form the start, but maybe these master neurons should have silencing connections toward their pupil neurons, instead of inhibiting connections.